
The dark genome represents one of the most fascinating and challenging frontiers in modern genetics. Comprising approximately 98% of our DNA, this vast non-protein-coding region was initially dismissed as "junk DNA."
However, scientific advances over the past two decades have revealed that the dark genome is anything but useless.
This unexplored genomic territory harbors a complex network of regulatory elements, repetitive sequences, and non-coding RNAs that play a vital role in modulating gene expression, chromatin structure, and ultimately, cellular function.
The importance of the dark genome lies in its ability to influence nearly every aspect of our biology. From embryonic development to environmental response, and the evolution of biological complexity, the dark genome acts as a sophisticated control system that fine-tunes the activity of our protein-coding genes.
Its study is redefining our understanding of genetics and opening new avenues for diagnosing and treating complex diseases.
History and Definition of the Dark Genome
The history of the dark genome is intimately linked to the Human Genome Project, a scientific milestone completed in 2003. This ambitious project, which cost nearly $3 billion and required 13 years of work, aimed to sequence and map all the genes in the human genome. However, the result was surprising: only about 2% of our DNA codes for proteins.
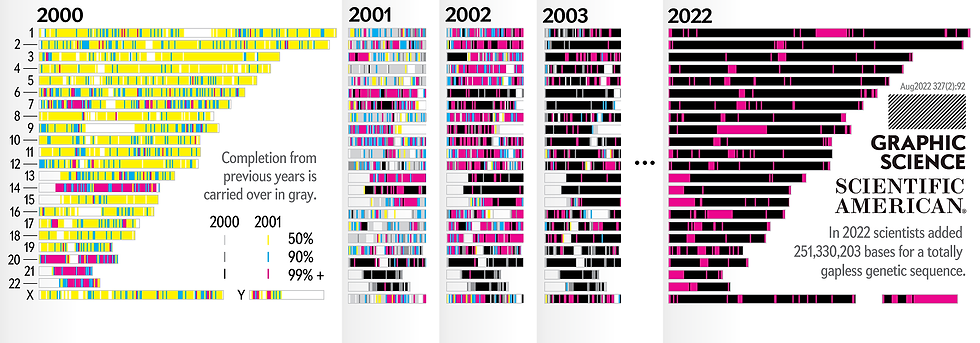
This discovery raised a fundamental question:
What function does the remaining 98% of the genome serve?
Initially, many scientists considered this vast non-coding region to be simply "junk" or residual DNA, vestiges of our evolutionary history with no apparent function. However, this view quickly changed.
The term "dark genome" was coined to refer to these mysterious regions of DNA. As researchers delved deeper into its study, it became evident that the dark genome was far from useless. On the contrary, it was discovered to contain a large number of crucial regulatory elements, repetitive sequences, and genes that produce non-coding RNAs, all of which play vital roles in gene regulation and cellular function.
Today, we define the dark genome as those regions of DNA that do not directly code for proteins but possess essential regulatory and structural functions. These regions include transposable elements, repetitive sequences, enhancers, silencers, and non-coding RNA genes, among other elements.
Far from being "dark" in the sense of useless, the term now reflects how much we still have to discover about these fascinating regions of our genome.
Components of the Dark Genome: Genome, Transcriptome, and Proteome
The study of the dark genome encompasses three main levels of biological organization:
The genome, transcriptome, and dark proteomes.
Each of these levels provides a unique and complementary perspective on the complexity of our genetic material. The dark genome, in its strictest sense, includes a wide variety of genetic elements:
Transposable elements:
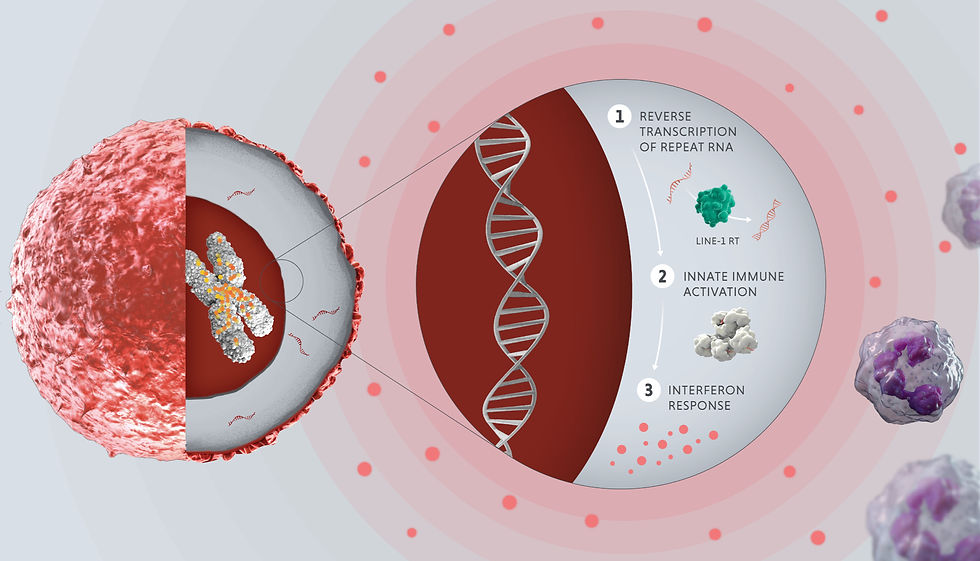
Such as LINEs (Long Interspersed Nuclear Elements), SINEs (Short Interspersed Nuclear Elements), and HERVs (Human Endogenous Retroviruses), constitute a large part of the dark genome.

These "jumping genes" have the ability to move and insert themselves in different locations within the genome, contributing to genetic diversity and, occasionally, to genetic diseases.
Repetitive sequences:
Including tandem repeats and dispersed repeats, are also part of the dark genome. Although initially thought to be irrelevant, we now know that these sequences can influence the three-dimensional structure of DNA and gene regulation.

Additionally, the dark genome harbors important regulatory regions such as enhancers and silencers, which act as molecular switches to control the expression of distant genes.
The dark transcriptome:
Comprises non-coding RNAs produced from the dark genome. These include:
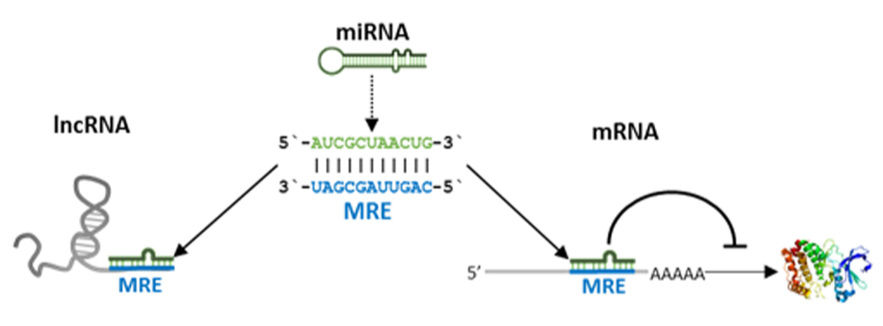
Long non-coding RNAs (lncRNAs), which can be thousands of nucleotides long and play crucial roles in gene regulation and development.
MicroRNAs (miRNAs)
Small interfering RNAs (siRNAs) are shorter molecules that participate in post-transcriptional regulation of gene expression.
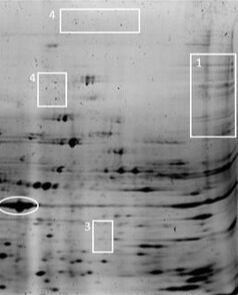
The dark proteome, although it may seem contradictory, refers to proteins that, despite being encoded by genes, remain poorly characterized or are difficult to study. This includes low-abundance proteins that are hard to detect with current techniques, intrinsically disordered proteins that lack a stable three-dimensional structure, and uncommon protein isoforms.
The study of the dark proteome is expanding our understanding of the diversity and complexity of protein functions in the cell.
The interaction between these three levels of the dark genome creates an incredibly complex regulatory network that influences almost every aspect of cellular and organismal biology. Unraveling these interactions is one of the most exciting and ambitious challenges of modern genetics.
Importance of the Dark Genome in Biomedicine
The relevance of the dark genome in biomedicine is becoming increasingly evident and is transforming our understanding of health and disease. Far from being an inert region of the genome, non-coding DNA plays a crucial role in numerous fundamental biological processes.
First and foremost, the dark genome is essential for regulating gene expression. Regulatory elements such as enhancers and silencers, often located at great distances from the genes they control, act as molecular switches that can activate or deactivate genes in response to various signals. This precise regulation is especially relevant for normal development and cellular homeostasis.
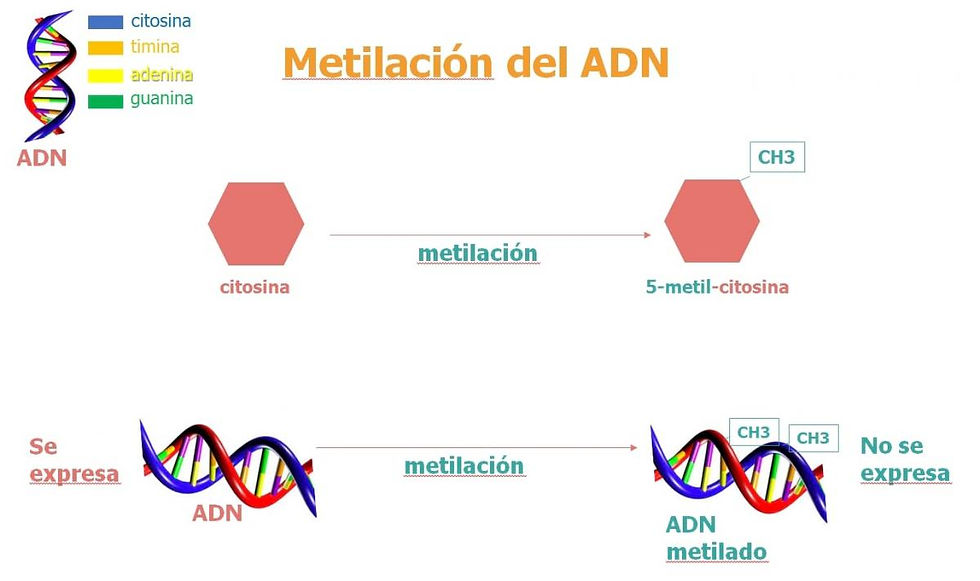
Epigenetic control, another fundamental aspect of gene regulation, is intimately linked to the dark genome. Epigenetic modifications, such as DNA methylation and histone modifications, frequently occur in non-coding regions and can dramatically alter gene expression without changing the underlying DNA sequence. Understanding these mechanisms is opening new avenues for treating diseases like cancer, where epigenetic alterations play a significant role.
The dark genome is also crucial for embryonic development and cell differentiation. Many long non-coding RNAs (lncRNAs) are specific to certain tissues or developmental stages, and their controlled expression is essential for the proper formation of organs and tissues. Alterations in these lncRNAs can lead to developmental disorders and congenital malformations.
Moreover, the dark genome plays a fundamental role in adapting to environmental stress. Certain elements of the dark genome, such as transposons, can be activated in response to stress factors, generating genetic variability that may be beneficial for adaptation. This mechanism is particularly relevant in the context of climate change and disease resistance.
In the field of evolution, the dark genome has been a major driver of biological complexity.
The expansion and diversification of non-coding regulatory elements have allowed the development of more sophisticated regulatory networks, contributing to the evolution of more complex organisms.
Finally, the dark genome is deeply implicated in various genetic diseases and cancer.
Mutations in non-coding regulatory regions can dramatically alter gene expression and contribute to disease development. In cancer, numerous alterations have been identified in non-coding regions that contribute to tumor progression and metastasis.
The growing appreciation of the dark genome's importance is revolutionizing the field of personalized medicine. By considering not only coding genes but also regulatory regions and non-coding RNAs, doctors can obtain a more complete picture of a patient's genetic profile, allowing for more accurate diagnoses and personalized treatments.
Challenges in Studying the Dark Genome
Despite its importance, studying the dark genome presents numerous challenges that researchers are working hard to overcome. These obstacles range from technical difficulties to conceptual complexities in data interpretation.
One of the main challenges is the inherent complexity of repetitive sequences that abound in the dark genome. These repetitions make both precise sequencing and genome assembly difficult, as it's hard to determine the exact origin of each repetitive sequence. Long-read sequencing technologies are helping to address this problem, but we can still continue to improve.

The low abundance of certain transcripts and proteins derived from the dark genome also poses a significant challenge. Many non-coding RNAs are expressed at very low levels or only in specific cell types, making their detection and characterization difficult. This requires the development of increasingly sensitive sequencing and proteomics techniques.
Bioinformatic analysis of the large datasets generated in dark genome studies represents another major challenge. Identifying functional elements in vast stretches of seemingly non-functional sequence requires sophisticated algorithms and considerable computational power.
Moreover, the biological interpretation of these elements once identified is not simple and often requires exhaustive experimental validation and state-of-the-art sequencing equipment.
Limitations in sequencing techniques for complex genomic regions also hinder the study of the dark genome. Certain regions, such as centromeric and telomeric repeats, are notoriously difficult to sequence and analyze with current technologies. Overcoming these technical limitations is a priority for obtaining a complete picture of the dark genome.
Perhaps the most fundamental challenge is establishing clear causal relationships between elements of the dark genome and observable phenotypes. Since many elements of the dark genome have subtle or context-dependent effects, demonstrating their functional relevance may require complex and long-term experiments.
Despite these challenges, the field is advancing rapidly thanks to technological and conceptual innovations. The combination of new sequencing techniques, genomic editing tools like CRISPR-Cas9, and advanced bioinformatic approaches is allowing researchers to unravel the secrets of the dark genome at an unprecedented rate.
Applications of the Dark Genome in Medicine and Biotechnology
The study of the dark genome is opening up new and exciting possibilities in the field of medicine and biotechnology. As our understanding of these non-coding regions of the genome deepens, new applications are emerging that will change the diagnosis and treatment of diseases.
In the realm of drug development, the dark genome is providing new therapeutic targets. Long non-coding RNAs (lncRNAs), for example, are emerging as new solutions for treating various diseases, including cancer.
These lncRNAs often have tissue-specific or disease-specific functions, making them attractive for developing more precise therapies with fewer side effects. Additionally, the design of therapeutic RNAs based on dark genome sequences is gaining ground as a novel strategy for modulating genomic expression in genetic diseases.
Personalized medicine is another area greatly benefiting from the study of the dark genome. Non-coding RNA expression profiles are emerging as powerful biomarkers for disease diagnosis and prognosis.
For example, certain microRNA expression patterns have been associated with different types and stages of cancer, allowing for more precise tumor classification.
Moreover, consideration of variants in regulatory regions of the dark genome is improving the accuracy of genetic risk profiles, enabling more personalized prevention and treatment.
Medical diagnosis is also benefiting from advances in dark genome studies. New biomarkers based on non-coding RNAs are improving early detection of diseases such as cancer and neurodegenerative disorders. These biomarkers can often be detected in body fluids like blood or urine, allowing for less invasive and more accurate diagnostic tests.
Finally, the study of the dark genome is providing new insights into the mechanisms underlying complex diseases.
For example, certain lncRNAs have been discovered to play prominent roles in the progression of neurodegenerative diseases such as Alzheimer's.
In cancer, alterations in regulatory regions of the dark genome have been observed to be important drivers of tumor progression and metastasis. These insights are opening up new avenues for developing targeted therapies.
In the field of biotechnology, the study of the dark genome is inspiring new applications.
For example, regulatory elements discovered in the dark genome are being used to design more precise and efficient gene expression systems in model organisms and in the production of recombinant proteins.
As we better understand the dark genome, even more innovative applications in medicine and biotechnology will emerge. The potential to develop more precise therapies, earlier diagnoses, and personalized treatments is truly exciting.
Technologies Used to Explore the Dark Genome
The study of the dark genome has been made possible thanks to a series of innovative and revolutionary technological advances. These technologies are allowing researchers to unravel the mysteries of non-coding regions of the genome with unprecedented precision and depth.
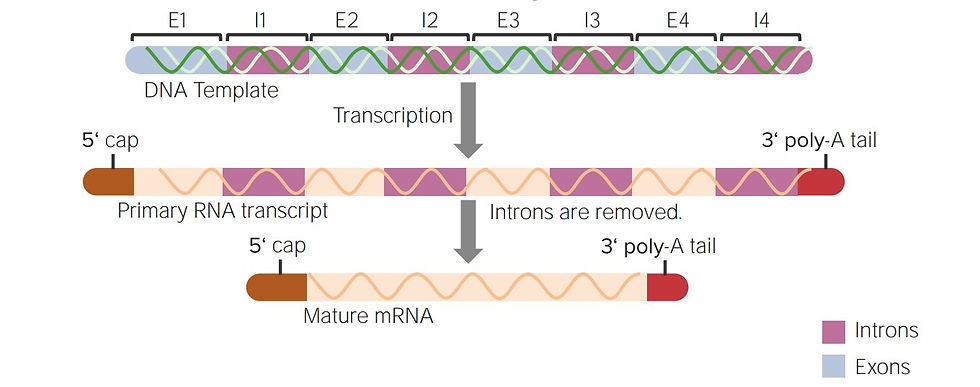
Next-generation sequencing (NGS) has been fundamental in this field. Techniques such as RNA-seq have allowed scientists to map the complete transcriptome, including low-abundance non-coding RNAs that were previously undetectable.
Thanks to this, we have been able to begin to understand the surprising complexity of the dark transcriptome, identifying thousands of new non-coding transcripts with potential regulatory functions.
Another very important technique for its reading is ChIP-seq (Chromatin Immunoprecipitation followed by sequencing), which allows mapping of protein-DNA interactions throughout the genome. This technique has been invaluable for identifying regulatory elements in the dark genome, such as enhancers and silencers, and for understanding how these elements interact with transcription factors to control gene expression.
Single-cell sequencing has also been achieved, allowing researchers to examine gene expression at the individual cell level, revealing cellular heterogeneity and enabling the detection of rare transcripts that might be lost in bulk cell population analyses.
This has been particularly useful for studying the function of the dark genome in development and cell differentiation.
Mass spectrometry has been very important in studying the dark proteome. Advanced proteomics techniques allow for the identification and characterization of low-abundance proteins and post-translational modifications, providing a more complete view of proteome diversity.
CRISPR-Cas9 technology has changed the way we study genome function. This genomic editing tool allows researchers to precisely modify specific elements of the dark genome and observe the resulting effects. This has been particularly useful for studying the function of regulatory elements and non-coding RNAs.
Finally, advances in bioinformatics and machine learning have been the before and after for analyzing and interpreting the large datasets generated by these technologies.
Sophisticated algorithms allow for the identification of patterns and relationships in the data that would be impossible to detect manually, helping to decipher the complex network of interactions in the dark genome.
The Future of the Dark Genome
The future of dark genome research promises to be as exciting as its recent past. All indications are that these advances and discoveries will transform our perception of medicine and our understanding of human biology.
One of the most promising areas is the development of RNA-based therapies for genetic diseases. As we better understand the role of non-coding RNAs in gene regulation, opportunities arise to develop therapies that specifically modulate these RNAs.
This could provide more precise and effective treatments for a variety of diseases, from cancer or neurological disorders to rare diseases.
Genome editing targeting regulatory elements is another area of great potential. With the refinement of genomic editing technologies like CRISPR-Cas9, we might be able to correct mutations in regulatory regions of the dark genome that cause diseases. This could open up new avenues for treating genetic diseases that currently have no cure.
The development of non-coding RNA-based biomarkers for early disease diagnosis is another area of intense research. These biomarkers could allow for the detection of diseases at very early stages, when treatment is most effective, completely changing preventive medicine.
As we unravel the secrets of the dark genome, we are also gaining a deeper understanding of human genome evolution. This could provide new perspectives on how we have evolved as a species and how we continue to adapt to our environment.
In the field of biotechnology, knowledge of the dark genome could lead to the development of synthetic organisms with optimized genomes. This could have applications in areas such as biofuel production, bioremediation, and pharmaceutical product production.
However, with these exciting possibilities also come ethical and regulatory challenges. As we gain the ability to manipulate increasingly large regions of the genome, including the dark genome, it will be necessary to carefully consider the ethical implications of these technologies.
As we continue to unravel the mysteries of these vast non-coding regions of our genome, we are discovering that they are anything but "dark" - in fact, they are shedding light on some of the most fundamental aspects of our biology.
And if you liked this, you might want to learn more about your DNA.
ความคิดเห็น